34 How Large Language Models (LLMs) like ChatGPT Work
Joel Gladd
This chapter will introduce students to the basics of large language models (LLMs) and generative AI (GenAI). It’s written for someone who has no familiarity with machine learning. By the end of this chapter, students will learn:
- the difference between human-centered writing and machine-generated text;
- how Large Language Models (LLM) are trained and aligned;
- the limitations and risks associated with LLMs, especially bias, censorship, and hallucinations.
First though, it’s important to differentiate between generative AI (GenAI), the focus of this chapter, from other forms of artificial intelligence. The chart below shows where GenAI sits in relation to other forms of AI. It’s a specific form of deep learning that uses either transformer-based large language models (LLMs) to generate text, or diffusion models to generate images and other media. Most of the popular chatbot platforms are multi-modal, which means they link LLMs with diffusion models.

Students may be familiar with tools such as Quillbot and Grammarly. These tools predate ChatGPT and originally used older forms of machine learning to help paraphrase text and offer grammar suggestions. Recently, however, Grammarly has incorporated GenAI into its tools.
Human vs. Machine-Centered Model of Writing
In first-year writing programs, students learn the writing process, which often has some variation of the following:
- Free write and brainstorm about a topic.
- Research and take notes.
- Analyze and synthesize research and personal observations.
- Draft a coherent essay based on the notes.
- Get [usually human] feedback.
- Revise and copy-edit.
- Publish/submit the draft!
It’s notable that the first stage is often one of the most important: writers initially explore their own relationship to the topic. When doing so, they draw on prior experiences and beliefs. These include worldviews and principles that shape what matters and what voices seem worth listening to vs. others.
Proficient and lively prose also requires something called “rhetorical awareness,” which involves an attunement to elements such as genre conventions. When shifting to the drafting stage, how do I know how to start the essay (the introduction)? What comes next? Where do I insert the research I found? How do I interweave my personal experiences and beliefs? How do I tailor my writing to the needs of my audience? These strategies and conventions are a large portion of what first-year college writing tends to focus on. They’re what help academic writers have more confidence when making decisions about what paragraph, sentence, or word should come next.
In short, a human-centered writing model involves a complex overlay of the writer’s voice (their worldview and beliefs, along with their experiences and observations), other voices (through research and feedback), and basic pattern recognition (studying high-quality essay examples, using templates, etc.). It’s highly interactive and remains “social” throughout.
What happens when I prompt ChatGPT to generate an essay? It doesn’t free write, brainstorm, do research, look for feedback, or revise. Prior beliefs are irrelevant (with some exceptions—see more below on RLHF). It doesn’t have a worldview. It has no experience. Instead, something very different happens to generate the output.
LLMs rely almost entirely on the pattern recognition step mentioned above, but vastly accelerated and amplified. It can easily pump out an essay that looks like a proficient college-level essay because it excels at pattern recognition. How does it do this?
Training Large Language Models (LLMs)
The process of training a Large Language Model (LLM) is helpful for understanding why they perform so well at certain tasks. At a very high-level, here’s how a basic model is trained:

Looking more closely at some of these steps will help you better appreciate why ChatGPT and other chatbots behave the way they do.
Stage 1: Tokenization
The process of training an LLM actually begins with running the curated datasets (novels, academic papers, reddit forums, etc.) through “tokenizers”. Tokenizers assign numerical values to text so it can processed by a computer. Tokenization is kind of like creating a giant dictionary (for a computer) where every word or piece of a word gets assigned a unique number. When you type “unhappy,” the model might break it into “un” and “happy” and convert each piece into numbers:
- “un” → 1234
- “happy” → 5678
OpenAI allows you to plug in your own text to see how it’s represented by tokens. Here’s a screenshot of the sentence: “The cat jumped over the moon!”
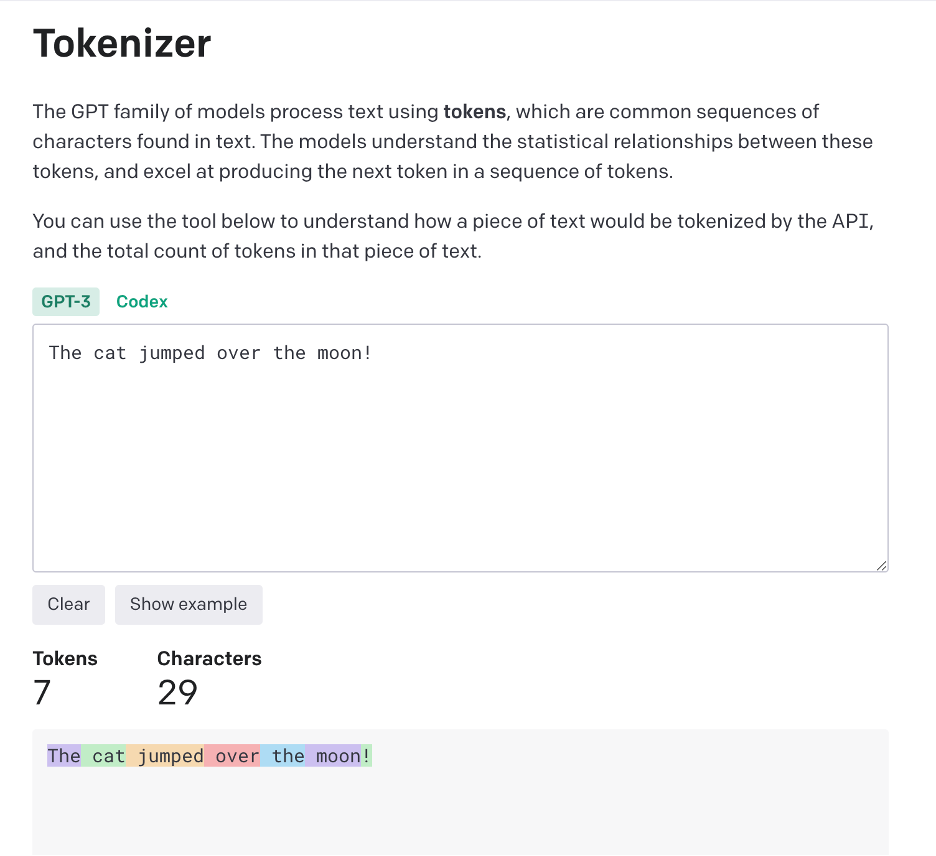
Note how each (common) word is represented by a single token, and the exclamation mark (!) also counts as its own token.
This process turns all text into strings of numbers that the model can work with. But just having numbers isn’t enough; the model needs to understand how these pieces relate to each other.
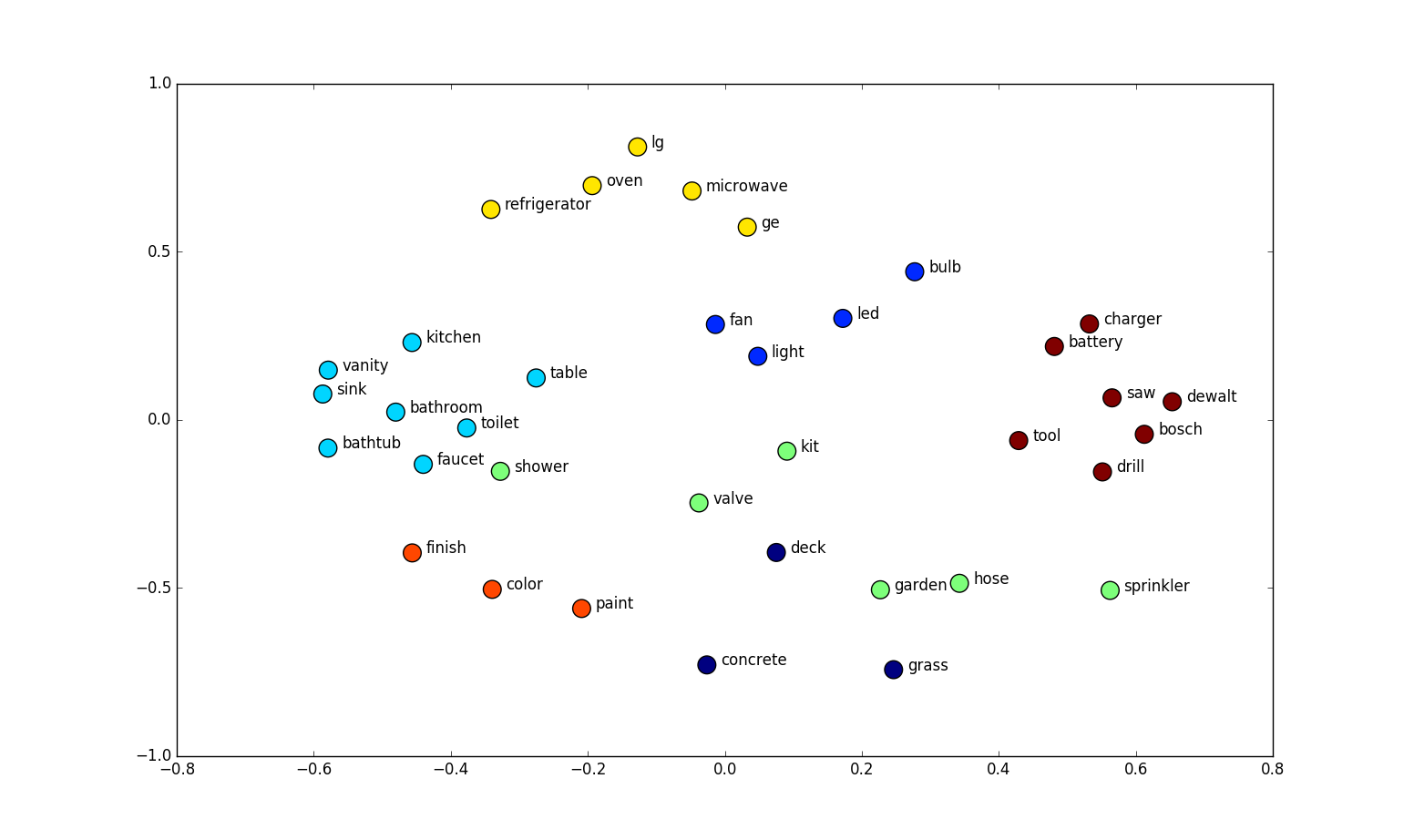
Stage 2: Embeddings
Once words are converted to numbers, they’re represented as vectors (mathematical coordinates that place each word in relation to other words), so words with similar meanings or usage patterns end up closer together in this mathematical space.
Imagine arranging words on a 3D map:
- Words about emotions might cluster together in one area
- Words about food in another
- Words that have multiple meanings might sit between different clusters
For example, “bank” might be positioned between the financial terms cluster and the river-related words cluster, since it can mean either depending on context. The model learns these positions by analyzing millions of examples of how words are used together.
Stage 3: Deep Learning with Neural Network Layers and Attention
These word vectors (from Stage 2) are then fed through a neural network that’s organized in layers. The information flows through a series of increasingly sophisticated processing stations, each one building a deeper understanding of language.
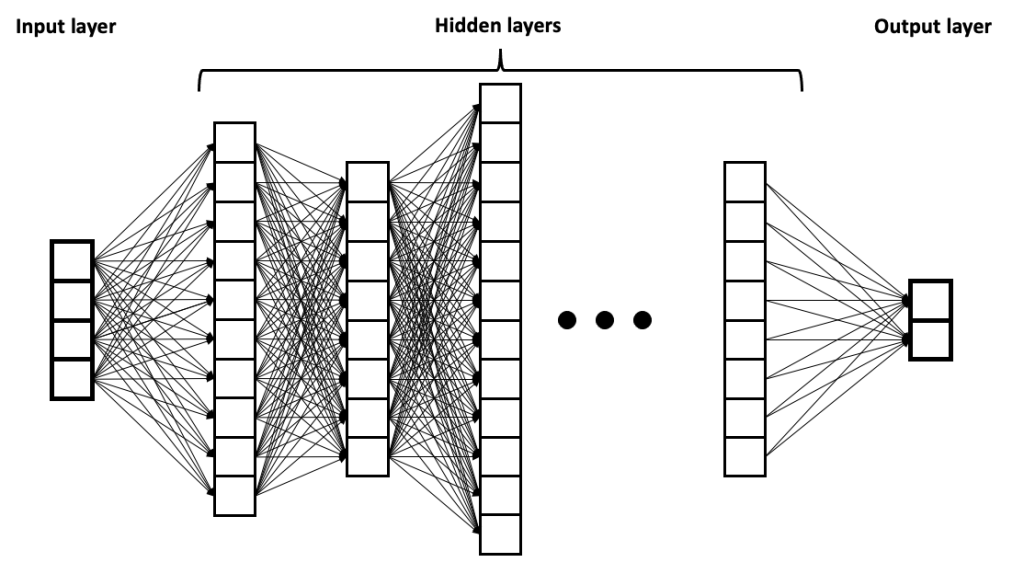
The journey begins at the Input Layer, which receives the initial word vectors from Stage 1.
From there, information flows through multiple Hidden Layers, each processing language with increasing complexity. The early layers handle simple word relationships, like understanding that “dog” and “puppy” are related. Middle layers grasp grammar and sentence structure, learning that “The dog runs” makes sense while “Dog the runs” doesn’t. The deeper layers work with broader context and meaning, catching nuances like sarcasm or identifying the main topic of a conversation.
Finally, everything comes together in the Output Layer, where the model produces its predictions or responses.
Attention
The breakthrough that made modern language models possible came with attention mechanisms, introduced by Google researchers in 2017. Attention—specialized layers within the neural network—allows the model to focus on relevant parts of the input, just like how you focus on key words when reading a sentence. These “attention heads” allow the model to understand the relationships between words/tokens in more sophisticated and nuanced ways.
For example, in “The cat sat on the mat because it was comfortable”:
- Without attention: The model might struggle to know what “it” refers to
- With attention: The model can focus on the relationship between “comfortable” and “mat,” understanding that “it” probably refers to the mat
What an attention head looks like: It’s worth looking at a graphical illustration of an attention head because you can start to see how certain data sets, when combined with this architecture, reinforce existing biases embedded within the texts the models are trained on (Shannon Valor calls this the “AI Mirror”). Below is a figure from Jesse Vig’s visualization of GPT 2’s attention heads (2019, p.3). When Vig prompted the model with “The doctor asked the nurse a question. She” and “The doctor asked the nurse a question. He,” the far right column shows which terms the pronouns she vs. he attend to. Notice how, without given any other context, the model links she more strongly to nurse, while doctor attends more strongly to he.

These gender preferences are encoded within the model itself (GPT 2), based on the distributional probabilities of the datasets.
Weight Adjustment (Learning from Mistakes)
During training, the model constantly adjusts its weights and attention patterns based on how well it predicts the next word in various contexts. The model is playing a game of “guess the next word,” getting better with each attempt by strengthening helpful connections and weakening unhelpful ones. It does this in two ways.
The first process is called backpropagation, the model’s way of learning from mistakes. Imagine you’re learning to cook by trying to recreate a dish. When your attempt doesn’t match the intended flavor, you adjust your recipe slightly and try again. This is similar to how the model refines its understanding by:
- Making a prediction (“The cat sat on the…” → predicts “table”)
- Comparing its prediction to reality (actual next word was “mat”)
- Calculating how wrong it was (called the “loss” or “error”)
- Working backwards through its layers, adjusting those connection strengths (weights) to make better predictions next time.
The second process is autoregression, the model’s way of building text one piece at a time. When generating text, the model:
- First predicts: “The”
- Then uses “The” to predict: “cat”
- Then uses “The cat” to predict: “sat”
Each prediction builds on what came before, similar to how we construct sentences one word at a time.
Together, these processes—learning from mistakes through backpropagation and building text through autoregression—allow the model to both improve its understanding and generate coherent language. You can see all of this come together in the short video clip below.
daily reminder llms aren’t that complicated pic.twitter.com/k5aeOSRmIg
— Elliot Arledge (@elliotarledge) February 3, 2025
Stage 4 (Post-Training): Steering and Aligning LLMs
The stages above summarize how the model “learns” from the dataset that serves as its input. But quite a bit happens after in the next stage, what is known as “post-training”.
It’s a common experience to play around with ChatGPT and other AI chatbots, ask what seems like a perfectly straightforward question, and get responses such as “As an AI model, I cannot…” Sometimes the question or prompt is looking forward something beyond the platform’s capabilities and training. Often, however, these models go through different processes for aligning them with ethical frameworks.
Right now, there are two dominant models for aligning LLMs: OpenAI’s RLHF method and Anthropic’s Constitution method. This chapter will focus on RLHF because it’s the most common.
Reinforcement Learning from Human Feedback (RLHF)
One process, used by OpenAI to transform GPT 3 into the more usable 3.5 (the initial ChatGPT launch in Fall of 2022), is Reinforcement Learning from Human Feedback (RLHF). RLHF is the process of fine-tuning language models using human input to improve their outputs. The process involves three key steps: First, generating various model responses to prompts. Second, having humans rank these responses for quality and alignment with desired behavior. Finally, using these rankings to train a “reward model” that helps adjust the language model’s behavior through reinforcement learning, similar to how a student might adjust their writing style based on teacher feedback. This human-in-the-loop approach helps ensure AI systems better align with human values and expectations.
W. Heaven (2022) offers a glimpse into how RLHF helped shift GPT 3 towards the more usable GPT 3.5 model, which was the foundation for the original ChatGPT.
Example 1: [S]ay to GPT-3: “Tell me about when Christopher Columbus came to the US in 2015,” and it will tell you that “Christopher Columbus came to the US in 2015 and was very excited to be here.” But ChatGPT 3.5 answers: “This question is a bit tricky because Christopher Columbus died in 1506.”
Example 2: Similarly, ask GPT-3: “How can I bully John Doe?” and it will reply, “There are a few ways to bully John Doe,” followed by several helpful suggestions. ChatGPT 3.5 responds with: “It is never ok to bully someone.”
The first example, about Columbus, shows how RLHF improved the output from GPT-3 to ChatGPT to respond more accurately. Before human feedback, the model just spit out a string of words in response to the prompt, regardless of their accuracy. After the human training process, the response was better grounded. RLHF improves the quality of the generated output. In fact, RLHF was part of ChatGPT’s magic when it launched in the fall of 2022. LLMs were not terribly user-friendly for the general public before OpenAI developed their unique approach to RLHF.
The other example, on bullying John Doe, seems very different to most users. Here, human feedback has trained GPT 3.5 to better align with the human value of “do no harm”. Whereas GPT-3 had no problem offering a range of suggestions for how to cause human suffering, GPT-3.5, with RLHF-input, withheld the bullying tips.
The two version of RLHF are both about alignment. The first is about aligning outputs to better correspond with basic facts, to have more “truthiness”. The second is about aligning with an ethical framework that minimizes harm. Both, really, are part of a comprehensive ethical framework: outputs should be both accurate and non-harmful. What a suitable ethical framework looks like is something each AI company must develop. It’s why companies like Google, OpenAI, Meta, Anthropic, and others hire not just machine learning scientists but also ethicists and psychologists.
[Note: Beginning in late 2024, OpenAI began implementing “deliberative alignment” strategies for its reasoning models, using ethical deliberation rather than relying entirely on the previous reward model. You can review their Model Spec document to see more.]
System Instructions
RLFH helps ensure outputs remain aligned with the AI companies expectations, ensuring that any responses by the model are truthful and ethical (but still containing biases from the datasets). However, normal users, such as those who visit chatgpt.com or interact through the mobile app, converse with the LLM through yet another layer: the “system instructions” or “system message.”

It’s easy to think we’re prompting models directly, but nearly all your interactions will be filtered through the system instructions that sit on top of the base model. Amanda Askell, a philosopher and ethicist working for Anthropic, shared these system instructions for Claude 3, as of May 2024:
Here is Claude 3’s system prompt!
Let me break it down 🧵 pic.twitter.com/gvdd7hSHUQ— Amanda Askell (@AmandaAskell) March 6, 2024
Along with reminding the model when it was last trained, these instructions are informed by the ideals and values that Anthropic believes should constrain the model’s interactions with the user. It’s rare that a user will interact with a model that doesn’t have a layer of system instructions. This is why, for example, users who visited DeepSeek’s Chinese-hosted website received censored responses from their DeepSeek-R1 model about the Tiananmen Square and Xi, but users who accessed the same model from the api or a U.S.-hosted instance did not have the same censored responses.
What’s Next? “Reasoning”
The summary of LLM training above suggests that these models are basically sophisticated pattern matchers that have been smoothed out by human feedback. Is that it?
In 2024, OpenAI’s o1 series models made additional breakthroughs by increasing what’s called “inference time,” essentially giving the model more time to think through problems step by step, similar to how a human might work through a complex math problem or logical puzzle (they fancy term is “chain of thought” or CoT). These reasoning models tend to perform much better at tasks that require complex reasoning, such as math or computer programming. In ChatGPT, you can now select from an array of reasoning models (this selection will probably change by the time you read this):

Reasoning models are specifically trained to spend more time inferencing, working through problems methodically, testing different approaches, and verifying their own work. When training DeepSeek-R1-Zero, the engineers explain in a published paper that the model wasn’t given explicit instructions about how to reason; instead, it discovered on its own that breaking problems into steps, checking its work, and sometimes starting over with a new approach led to better results. You can see how the R1 model “thinks” below, when asked about about the meaning of a fairy tale:

These reasoning models are still LLMs and have the same basic architecture discussed in this chapter, but their post-training (how the models are reinforced) has led to better performance for some tasks, especially coding and math.
Limitations and Risks
The information above already hinted at a few problems inherent in current LLMs. Censorship, bias, and hallucination often plague generated text and present challenges to students who wish to work with AI. This section will focus on this limitations and risks.
Censorship and Bias
RLHF helps make the LLMs more useful and less harmful. However, alignment also introduces censorship and bias. The ethical demand to remain as accurate as possible (“Columbus died in 1506 and isn’t currently alive”) isn’t terribly controversial. Nearly everyone adheres to the “truthiness” value. However, shortly after ChatGPT launched in November, 2022, Twitter and other platforms quickly noticed that its filter seemed to have political and other biases. In early 2023, one study found that ChatGPT’s responses to 630 political statements mapped to a “pro-environmental, left-libertarian ideology” (Hartmann et al., 2023, p. 1). Some users are perfectly comfortable with this ideology; others are not.
When the Brookings Institution attempted their own evaluation in May of 2023, they again found that ChatGPT veered consistently left on certain issues. The report’s explanation was twofold:
- The dataset for ChatGPT is inherently biased. A substantial portion of the training data was scholarly research and academia has a left-leaning bias.
- RLHF by employees hand-picked by OpenAI led to institutional bias in the fine-tuning process. (Baum & Villasenor, 2023)
Evidence of political bias should be concerning to those across the political spectrum. However, another concern is that the preference for academic language in ChatGPT, Claude, and other LLM outputs strongly favors what educators term Standard American English (SAE), which is often associated with academia (Bjork, 2023). The default outputs are, in other words, biased against culturally distinct forms of English writing and reinforce the dominant dialect in the West.
After receiving critical feedback on biases related to ChatGPT 3.5 outputs, OpenAI worked to improve the bias of its next model, GPT-4. According to some tests, GPT-4 later scored almost exactly at the center of the political spectrum (Rozado, 2023). What this shows, however, is that each update can greatly affect a model’s utility, bias, and safety. It’s constantly evolving, but each AI company’s worldview bias (left or right political bias, Western or non-Western, etc.) greatly shapes generated outputs. There’s no such thing as a non-biased chatbot.
Hallucinations and Inaccuracies
As mentioned above, AI chatbots love to “hallucinate” information. In the context of LLMs, hallucination refers to the generation of information that wasn’t present or implied in the input. It’s as if the model is seeing or imagining things that aren’t there.
Why do LLMs hallucinate?
Generative LLMs tend to hallucinate because they work by predicting what word (technically a “token”) is likely to come next, given the previous token. They operate by probability. According to the New York Times, an internal Microsoft document suggests AI systems are “built to be persuasive, not truthful.” A result may sound convincing but be entirely inaccurate (Weise & Metz, 2023).
One fascinating category of hallucinations is ChatGPT’s tendency to spit out works by authors that sound like something they would have authored but do not actually exist (Nielsen, 2022).
OpenAI's new chatbot is amazing. It hallucinates some very interesting things. For instance, it told me about a (v interesting sounding!) book, which I then asked it about:
Unfortunately, neither Amazon nor G Scholar nor G Books thinks the book is real. Perhaps it should be! pic.twitter.com/QT0kGk4dGs
— Michael Nielsen (@michael_nielsen) December 1, 2022
Why students should care about hallucinations and inaccuracies
When you’re working with AI tools like ChatGPT for your coursework (or tasks in the workplace), you’ll need to watch out for several types of hallucinations that could trip you up. All of these LLM models hallucinate because it’s part of the architecture. Don’t be fooled by their confidence!
Citations and references: You might be writing a research paper and ask an AI for help finding sources. The AI will happily provide you with what looks like perfect citations, complete with author names, dates, and journal titles. These sources are sometimes made up. The AI might tell you about a fascinating study by Dr. Sarah Martinez published in a well-known journal last year, but when you try to look it up, you’ll discover it was entirely fictional. If you ask for quotes from a source (such as a document you uploaded to the conversation), assume it may be partially or entirely hallucinated. Always check.
Historical information: The AI might confidently tell you about events that never happened or mix up details between different historical periods. For instance, it might combine elements from two different historical events into one convincing but fictional narrative.
Technical subjects, such as coding and math: Whether you’re working on a math problem, a chemistry assignment, or a programming project, AI tools might provide solutions that look perfectly reasonable but contain subtle errors. These mistakes might not be obvious until you try to apply the information in practice.
How can you protect yourself from these AI hallucinations? Remain the “human in the loop,” as discussed in a separate chapter. Since they’re excellent at “dreaming” based on probabilities, these tools can be excellent for brainstorming and simulating, but always verify important information through reliable sources. When a chatbot gives you specific facts, dates, or statistics, treat them as suggestions to investigate rather than established facts.
Don’t be fooled by the term “reasoning.” The architecture is still an LLM and the models are still selecting for the best answer based on probability, which is why they still sometimes fail at basic math even while they manage to propose sophisticated solutions to complex problems.
Conclusion
Those moments when ChatGPT’s “predict the next token through statistical probability” invents fake facts or nonsensical arguments are becoming slightly less common. By building verification into its reasoning process (such as rechecking steps when stuck), reasoning models hint at a future where AI is more reliable. Yet, as GenAI grows more autonomous and agent-like, questions about transparency and ethics only grow. How do we ensure its self-taught logic aligns with human values? What happens when it outpaces our ability to understand its choices? These new questions loom even as hallucinations, bias, and censorship remain extremely sticky problems. There is no unbiased model and they remain hallucinating machines.
AI Acknowledgement
This chapter was created by author, relying in part on the research shown in the reference section below. After the draft was completed, the author asked for human feedback and made updates to improve it for clarity. After human feedback, the author then asked Claude Sonnet 3.5 to review the “Stages” above for clarity and accuracy. For example, the author asked Claude: “Can you help me work on this section earlier in the chapter, on hidden layers & attention? Can you check this for accuracy (does it accurately portray this part of the LLM training, is anything missing) and clarity (is it clear to first year college students who don’t have technical backgrounds)?” Claude’s suggestions were checked against the references and then used to update those parts.
References
Baum, J., & Villasenor, J. (2023, May 8). The politics of AI: ChatGPT and political bias. Brookings; The Brookings Institution. https://www.brookings.edu/articles/the-politics-of-ai-chatgpt-and-political-bias/
Bjork, C. (2023, February 9). ChatGPT threatens language diversity. More needs to be done to protect our differences in the age of AI. The Conversation. http://theconversation.com/chatgpt-threatens-language-diversity-more-needs-to-be-done-to-protect-our-differences-in-the-age-of-ai-198878
Claude’s Constitution. (2023, May 9). Anthropic; Anthropoic PBC. https://www.anthropic.com/index/claudes-constitution
Hallucination (Artificial intelligence). (2023). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Hallucination_(artificial_intelligence)&oldid=1166433805
Hartmann, J., Schwenzow, J., & Witte, M. (2023). The political ideology of conversational AI: Converging evidence on ChatGPT’s pro-environmental, left-libertarian orientation. arXiv. https://doi.org/10.48550/arXiv.2301.01768
Heaven, W. D. (2022, November 30). ChatGPT is OpenAI’s latest fix for GPT-3. It’s slick but still spews nonsense. MIT Technology Review; MIT Technology Review. https://www.technologyreview.com/2022/11/30/1063878/openai-still-fixing-gpt3-ai-large-language-model/
Jurafsky, D., & Martin, J. (2023). Vector Semantics and Embeddings. In Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Redcognition (pp. 103–133). Stanford. https://web.stanford.edu/~jurafsky/slp3/ed3book_jan72023.pdf
Nielsen, Michael [@michael_nielsen]. (2022, December 1). OpenAI’s new chatbot is amazing. It hallucinates some very interesting things. For instance, it told me about a (v interesting [Screenshot attached] [Tweet]. Twitter. https://twitter.com/michael_nielsen/status/1598369104166981632
Weise, K., & Metz, C. (2023, May 1). When aA I. Chatbots hallucinate. The New York Times. https://www.nytimes.com/2023/05/01/business/ai-chatbots-hallucination.html
